网络爬虫——票房网数据抓取及MYSQL存储
实验内容
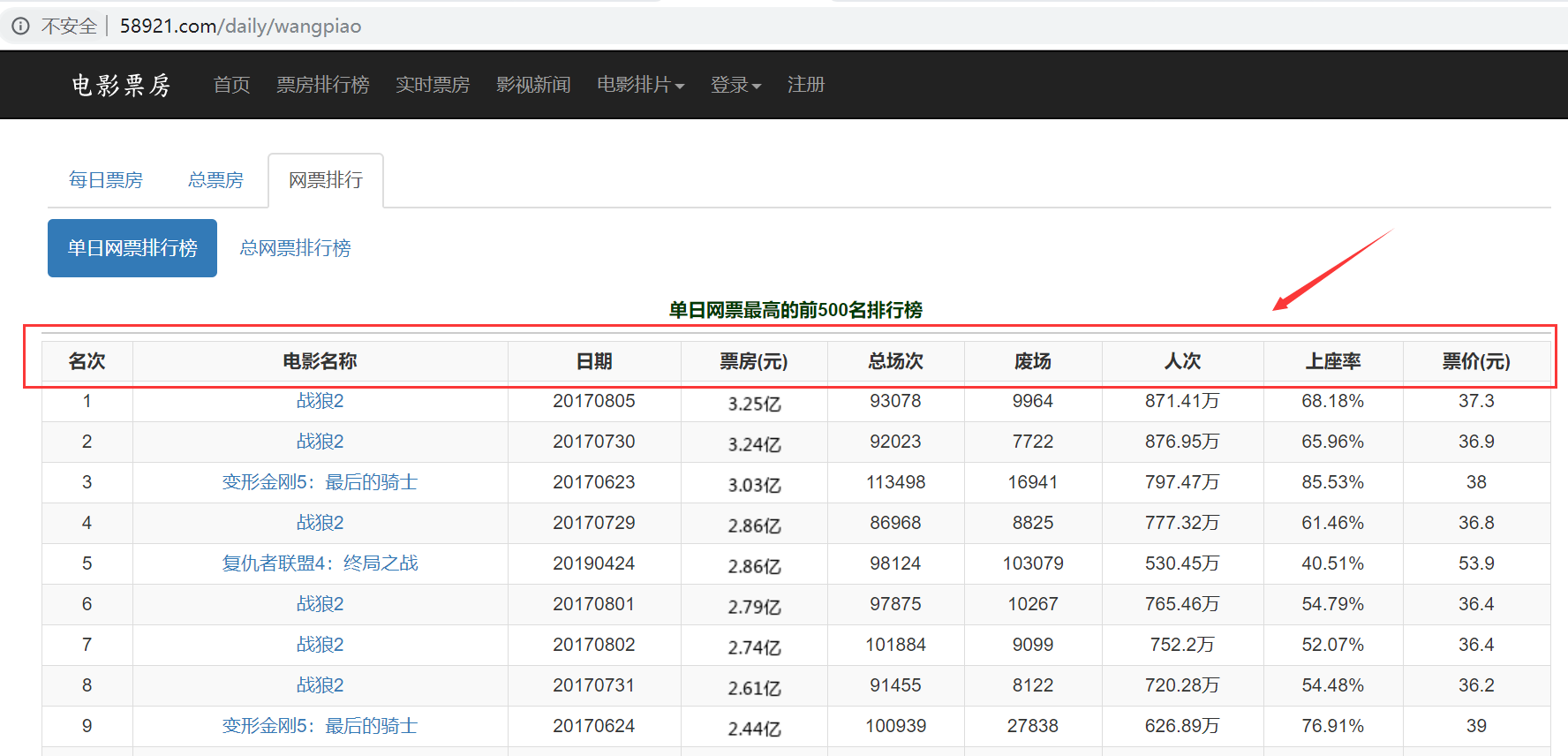
目标网站:电影票房网
目标网址:http://58921.com/daily/wangpiao
任务要求
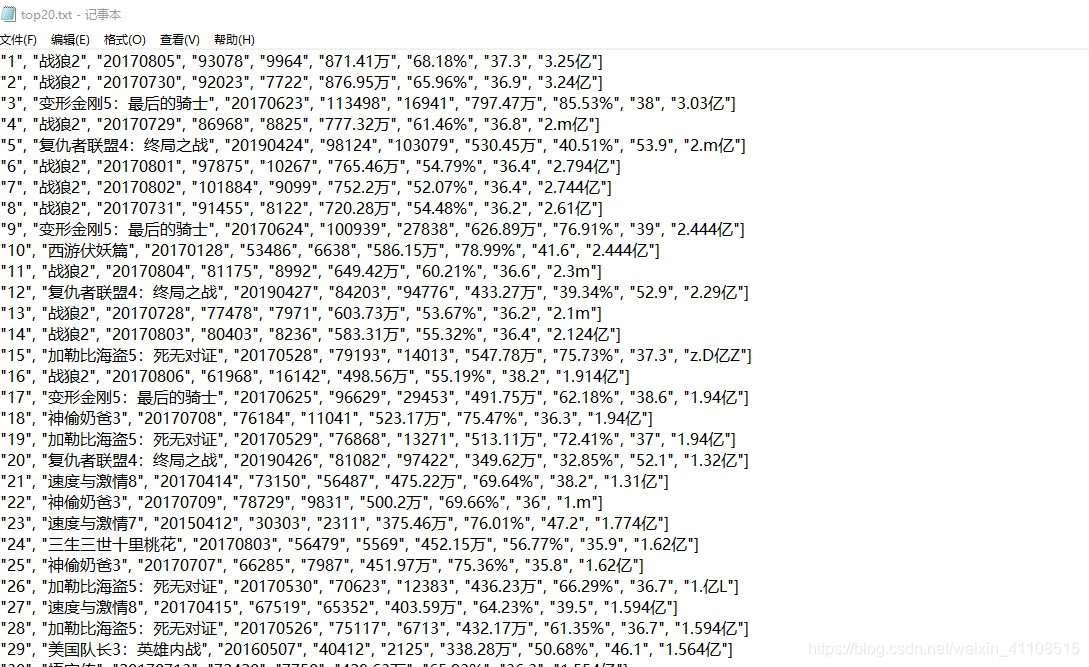
目标数据:(1)名次(2)电影名称 (3)日期(4)票房 (5)总场次(6)废场(7)人次(8)上座率(9)票价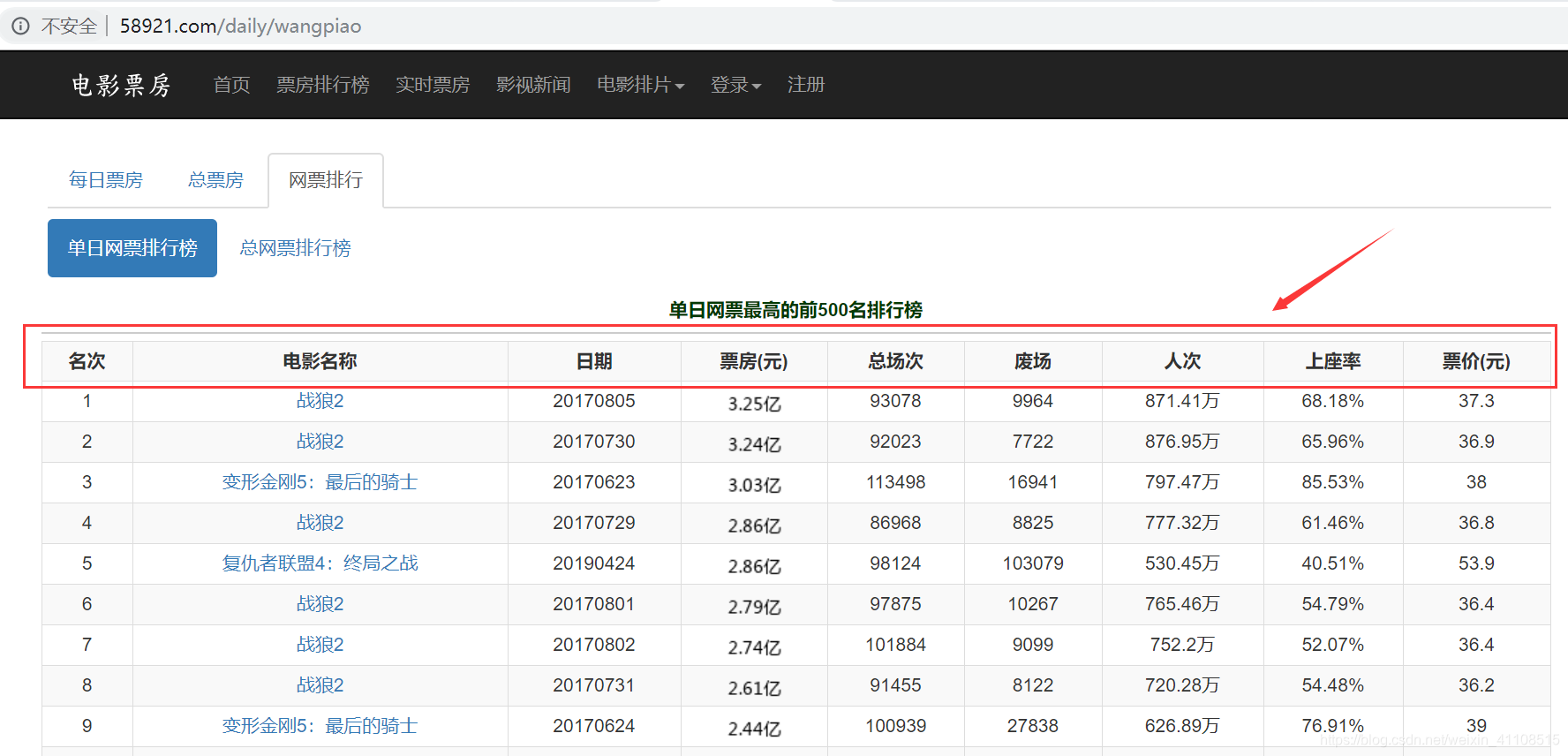
要求
(1)使用urllib或requests库实现该网站网页源代码的获取,并将源代码进行保存;
(2)自主选择re、bs4、lxml中的一种解析方法对保存的的源代码读取并进行解析,成功找到目标数据所在的特定标签,进行网页结构的解析;
(3)定义函数,将获取的目标数据保存到MYSQL库文件中。
(4)使用框架式结构,通过参数传递实现整个特定数据的爬取。
源码
import requests
import json
import csv
from requests.exceptions import RequestException
from lxml import etree
import pymysql
from PIL import Image
import pytesseract
import traceback
def connectMysql():
return pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spiders')
def createMysqlTable():
db = connectMysql()
cursor = db.cursor()
# fieldnames = ['名次','电影名称','日期','票房','总场次','废场','人次','上座率','票价']
sql = 'create table if not exists movies (\
名次 int not null ,\
电影名称 varchar(255) not null ,\
日期 varchar(255) not null,\
总场次 varchar(255) not null,\
废场 varchar(255) not null,\
人次 varchar(255) not null,\
上座率 varchar(255) not null,\
票价 varchar(255) not null,\
票房 varchar(255) not null,\
primary key(名次))'
cursor.execute(sql)
print('ok')
db.close()
def getHtmlText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69'
}
try:
result = requests.get(url,headers=headers,timeout=30)
result.raise_for_status()
result.encoding = result.apparent_encoding
return result.text
except:
return ""
def parsePage(html):
ulist = []
clist = []
rlist = []
ilist = []
newhtml =etree.HTML(html,etree.HTMLParser())
result=newhtml.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td//text()')
imgs = newhtml.xpath('//*[@id="content"]/div[2]/table/tbody/tr/td/a/img/@src', stream=True)
j = 0
for img in imgs:
j=j+1
with open(str(j)+'.png', 'wb') as fd:
picture=requests.get(img).content
fd.write(picture)
for i in range(len(imgs)):
str_ = str(i+1)+'.png'
text = pytesseract.image_to_string(Image.open(str_))
ilist.append(text.replace(" ",".").replace("M","亿").replace("a","亿"))
# print(ilist)
for i in range(len(result)):
ulist.append(result[i].replace(" ","").replace('\r',"").replace("\n",''))
while '' in ulist:
ulist.remove('')
length = len(ulist)
weight = int(length / 8 )
for i in range(weight):
for j in range(8):
clist.append(ulist[i*8+j])
clist.append(ilist[i])
rlist.append(clist)
clist = []
return rlist
def mysqlData(datas):
table = 'movies'
keys = '名次,电影名称,日期,总场次,废场,人次,上座率,票价,票房'
db = connectMysql()
cursor = db.cursor()
for data in datas:
values = ','.join(['%s']*len(data))
sql = 'INSERT INTO {table}({keys}) VALUES({values})'.format(table=table,keys = keys ,values = values)
print(sql)
print(tuple(data))
try :
if cursor.execute(sql, tuple(data)):
print("Succcessful")
db.commit()
except:
traceback.print_exc()
print("Failed")
db.rollback()
db.close()
def main():
createMysqlTable()
url="http://58921.com/daily/wangpiao"
html=getHtmlText(url)
rlist=parsePage(html)
mysqlData(rlist)
main()
结果输出效果: