网络爬虫——二手房数据抓取及MYSQL存储
目标网址:
https://qd.anjuke.com/sale/jiaozhoushi/?from=SearchBar
目标数据:
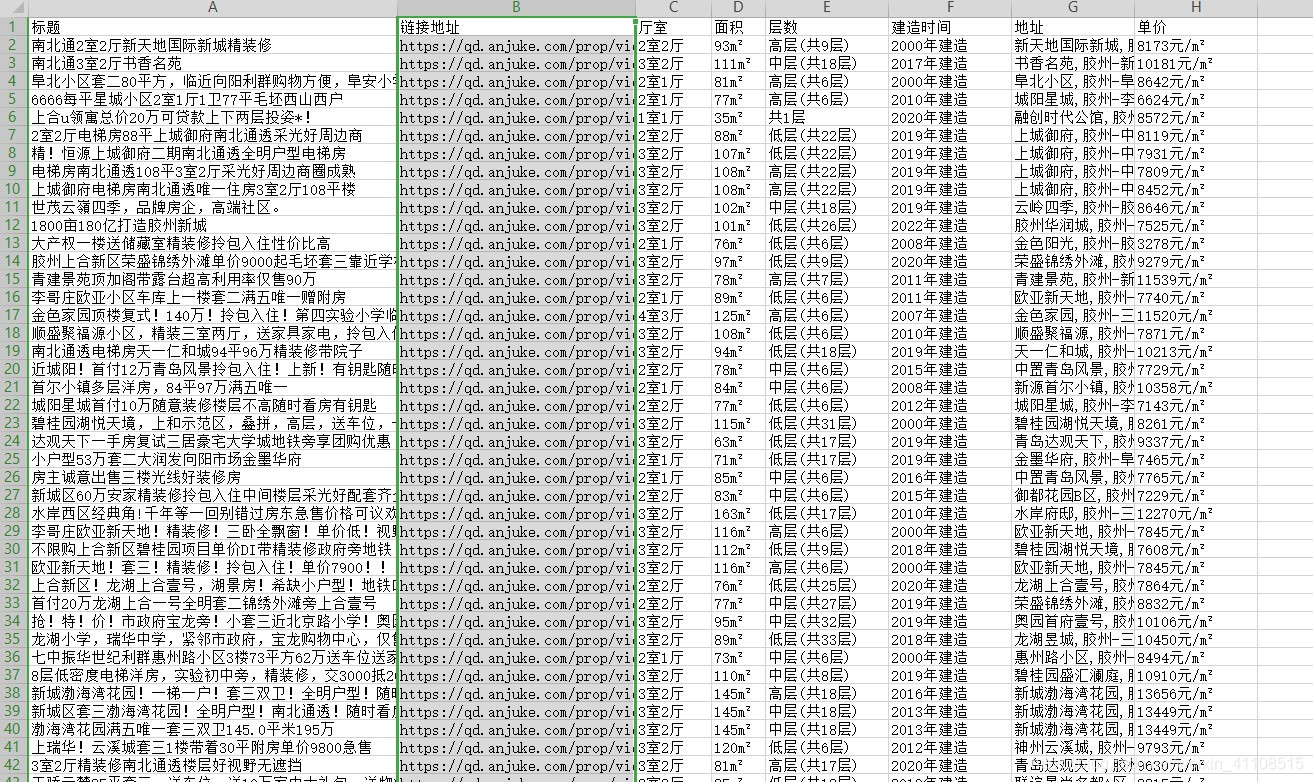
标题 + 链接地址 + 厅室+ 面积+ 层数+建造时间 + 地址 + 单价(或总价)
要求:
(1)自选请求库和解析库获取目标数据;
(2)第一个存储至txt或者csv中,第二个源码存储至Mysql中。
源码(1):csv,txt
import requests
import json
import csv
from requests.exceptions import RequestException
from lxml import etree
def getHtmlText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69'
}
try:
result = requests.get(url,headers=headers,timeout=30)
result.raise_for_status()
result.encoding = result.apparent_encoding
return result.text
except:
return ""
def cleanData(clist):
olist = []
for i in range(len(clist)):
olist.append(clist[i].replace(" ","").replace('\r',"").replace("\n",'').replace("\xa0\xa0",','))
return olist
def parsePage(html):
ulist = []
clist = []
newhtml =etree.HTML(html,etree.HTMLParser())
titles =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div/a//text()'))
hrefs = cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div/a//@href', stream=True))
others =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div[2]/span//text()'))
addresss =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div[3]/span//text()'))
prices =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[3]/span[2]//text()'))
length = len(titles)
for i in range(length):
ulist.append(titles[i])
ulist.append(hrefs[i])
ulist.append(others[i*4+0])
ulist.append(others[i*4+1])
ulist.append(others[i*4+2])
ulist.append(others[i*4+3])
ulist.append(addresss[i])
ulist.append(prices[i])
clist.append(ulist)
ulist = []
return clist
def txtdata(data):
with open('data.txt','w')as file:
for i in data:
for j in i:
print(j)
print('successful')
def storedata(data):
with open('data.txt','w',encoding = 'utf-8')as file:
for i in data:
file.write(json.dumps(i,ensure_ascii=False)+'\n')
print('ok')
def csvdata(data):
with open('data.csv','w',encoding = 'utf-8',newline='')as csvfile:
fieldnames = ['标题','链接地址','厅室','面积','层数','建造时间','地址','单价']
writer = csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writeheader()
for i in data:
writer.writerow({'标题':i[0],'链接地址':i[1],'厅室':i[2],'面积':i[3],'层数':i[4],'建造时间':i[5],'地址':i[6],'单价':i[7]})
print('ok')
def main():
url="https://qd.anjuke.com/sale/jiaozhoushi/?from=SearchBar"
html=getHtmlText(url)
rlist=parsePage(html)
txtdata(rlist)
storedata(rlist)
csvdata(rlist)
main()
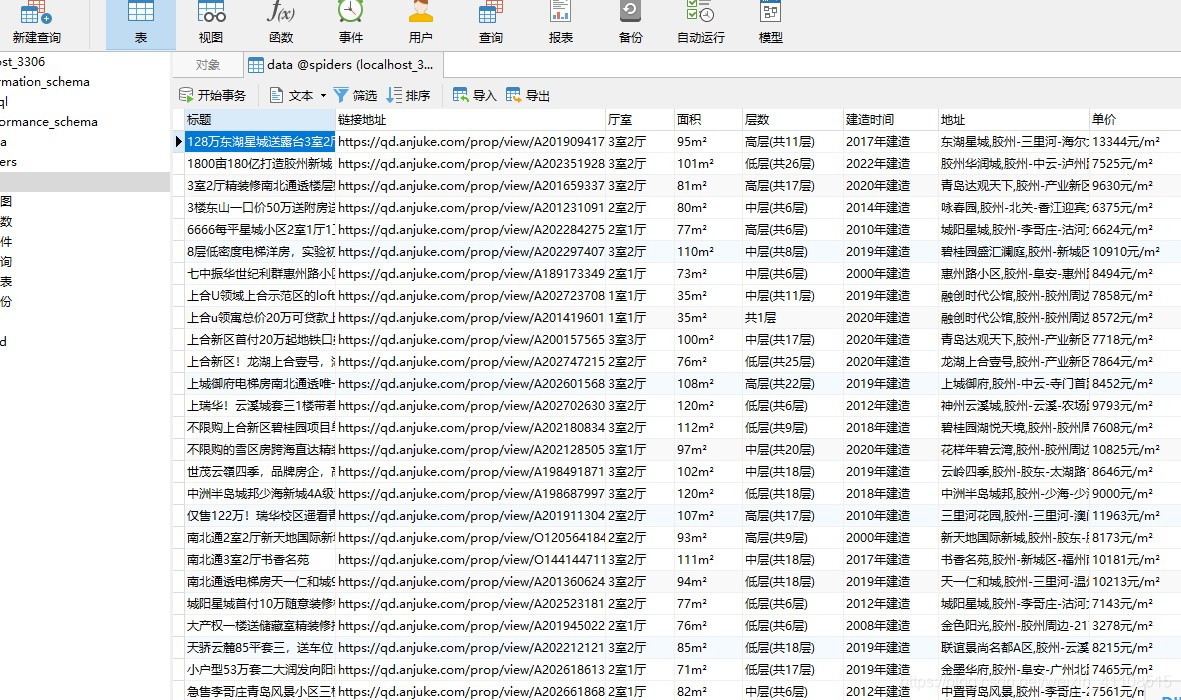
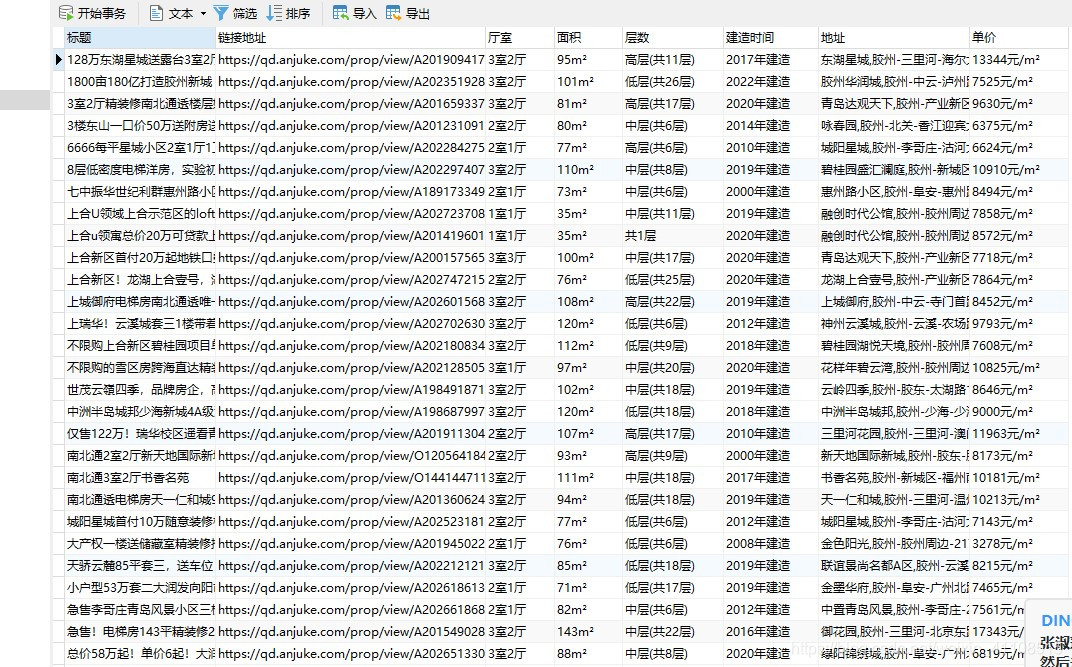
源码(1):MYSQL
import requests
import json
import csv
from requests.exceptions import RequestException
from lxml import etree
import pymysql
import pytesseract
import traceback
def connectMysql():
return pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spiders')
def createMysqlTable():
db = connectMysql()
cursor = db.cursor()
sql = 'create table if not exists data (\
标题 varchar(255) not null ,\
链接地址 varchar(255) not null ,\
厅室 varchar(255) not null,\
面积 varchar(255) not null,\
层数 varchar(255) not null,\
建造时间 varchar(255) not null,\
地址 varchar(255) not null,\
单价 varchar(255) not null,\
primary key(标题))'
cursor.execute(sql)
print('ok')
db.close()
def getHtmlText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69'
}
try:
result = requests.get(url,headers=headers,timeout=30)
result.raise_for_status()
result.encoding = result.apparent_encoding
return result.text
except:
return ""
def cleanData(clist):
olist = []
for i in range(len(clist)):
olist.append(clist[i].replace(" ","").replace('\r',"").replace("\n",'').replace("\xa0\xa0",','))
return olist
def parsePage(html):
ulist = []
clist = []
newhtml =etree.HTML(html,etree.HTMLParser())
titles =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div/a//text()'))
hrefs = cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div/a//@href', stream=True))
others =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div[2]/span//text()'))
addresss =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div[3]/span//text()'))
prices =cleanData(newhtml.xpath('//*[@id="houselist-mod-new"]/li/div[3]/span[2]//text()'))
length = len(titles)
for i in range(length):
ulist.append(titles[i])
ulist.append(hrefs[i][0:100])
ulist.append(others[i*4+0])
ulist.append(others[i*4+1])
ulist.append(others[i*4+2])
ulist.append(others[i*4+3])
ulist.append(addresss[i])
ulist.append(prices[i])
clist.append(ulist)
ulist = []
return clist
def txtdata(data):
with open('data.txt','w')as file:
for i in data:
for j in i:
print(j)
print('successful')
def storedata(data):
with open('data.txt','w',encoding = 'utf-8')as file:
for i in data:
file.write(json.dumps(i,ensure_ascii=False)+'\n')
print('ok')
def csvdata(data):
with open('data.csv','w',encoding = 'utf-8',newline='')as csvfile:
fieldnames = ['标题','链接地址','厅室','面积','层数','建造时间','地址','单价']
writer = csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writeheader()
for i in data:
writer.writerow({'标题':i[0],'链接地址':i[1],'厅室':i[2],'面积':i[3],'层数':i[4],'建造时间':i[5],'地址':i[6],'单价':i[7]})
print('ok')
def mysqlData(datas):
table = 'data'
keys = '标题,链接地址,厅室,面积,层数,建造时间,地址,单价'
db = connectMysql()
cursor = db.cursor()
for data in datas:
values = ','.join(['%s']*len(data))
sql = 'INSERT INTO {table}({keys}) VALUES({values})'.format(table=table,keys = keys ,values = values)
print(sql)
print(tuple(data))
try :
if cursor.execute(sql, tuple(data)):
print("Succcessful")
db.commit()
except:
traceback.print_exc()
print("Failed")
db.rollback()
db.close()
def main():
# createMysqlTable()
url="https://qd.anjuke.com/sale/jiaozhoushi/?from=SearchBar"
html=getHtmlText(url)
rlist=parsePage(html)
# txtdata(rlist)
storedata(rlist)
csvdata(rlist)
mysqlData(rlist)
main()