网络爬虫——搜狐最新时政新闻数据爬取
目标网址:https://www.sohu.com/c/8/1460?spm=smpc.null.side-nav.14.1584869506422WxyU9iK
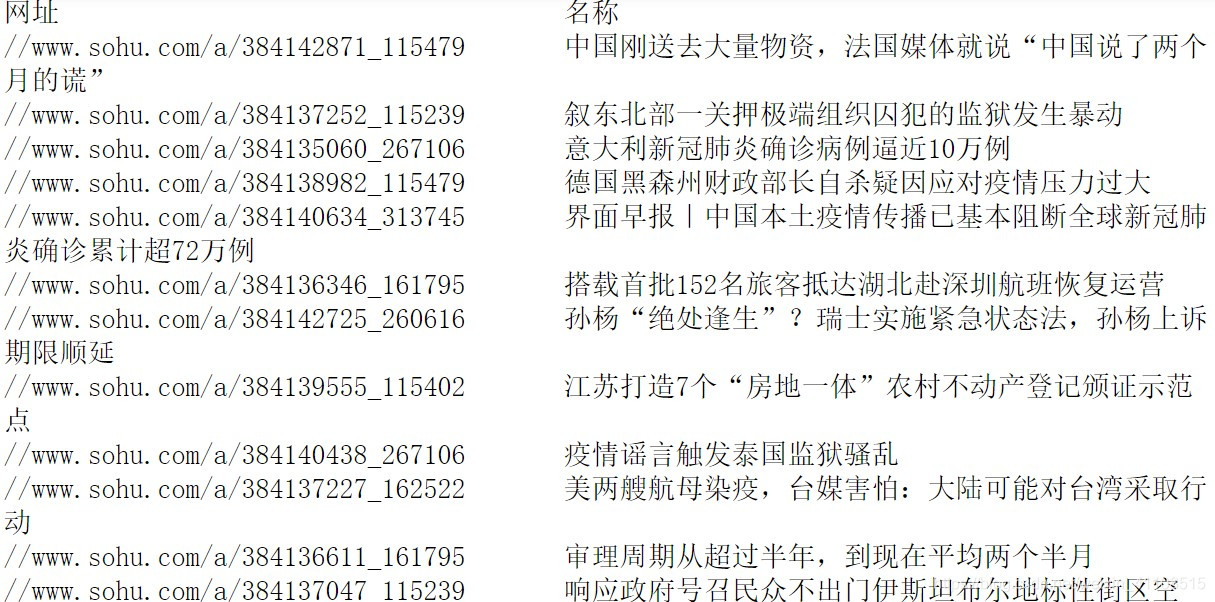
目标数据描述:(1)标题 (2)链接地址
要求:
(1)使用urllib库或者requests抓取网页源代码;
(2)使用BeautifulSoup的CSS选择器方法对获取的源代码进行解析,并成功找到目标数据所在的特定标签,进行网页结构的解析;
(3)利用框架结构,通过函数调用,参数传递,实现目标数据抓取,并尝试将结果写入文本文件中。
源码
import requests
from bs4 import BeautifulSoup
import bs4
def getHtmlText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69'
}
try:
result = requests.get(url,headers=headers,timeout=30)
result.raise_for_status()
result.encoding = result.apparent_encoding
return result.text
except:
print("A")
return ""
def findUniverse(ulist , html):
soup = BeautifulSoup(html,"html.parser")
for div in soup.find(attrs=['class','news-list clearfix']).children:
if isinstance(div ,bs4.element.Tag):
list_0 = div.find('h4').find('a').get('href')
list_1 = div.find('h4').string.replace(" ",'').replace("\n",'')
ulist.append([list_0,list_1])
def findSame(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for div in soup.find(attrs=['class','second-nav']).children:
if isinstance(div ,bs4.element.Tag):
ulist.append(div.find('a').get('href'))
return ulist
def printUniverse(ulist):
tplt = '{0:30}\t{1:18}'
print(tplt.format("网址","名称",chr(12288)))
for i in range(len(ulist)):
u = ulist[i]
print(tplt.format(u[0],u[1],chr(12288)))
def main():
ulist = []
ulist_Same = []
url = 'https://www.sohu.com/c/8/1460?spm=smpc.null.side-nav.14.1585491604691ZcX26aI'
html = getHtmlText(url)
ulist_Same = findSame(ulist_Same,html)
for i in range(len(ulist_Same) - 2 ):
url = 'https://www.sohu.com' + ulist_Same[i+1]
html = getHtmlText(url)
findUniverse(ulist,html)
printUniverse(ulist)
main()
输出如下: