网络爬虫——基于Bilibili热门视频Top100最热分区爬取与分析
这个主要是配合之前报告使用的,这里就不多赘述了。
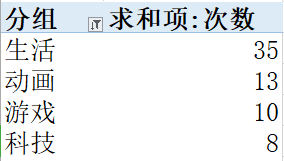
先爬地址,再爬取地址里的分区,最后整合。csv存储。
实验内容
目标网站:Bilibili热门视频Top100
目标网址:
https://www.bilibili.com/ranking?(每过几天都会变的哦)
from lxml import etree
import time
import jieba
import numpy as np
from PIL import Image
import requests
import re
from requests.exceptions import RequestException
from wordcloud import WordCloud as wc
import csv
class getUrl ():
def __init__(self,url):
self.url = url
def getTxt(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69'
}
try:
result = requests.get(self.url,headers=self.headers,timeout=30)
result.raise_for_status()
result.encoding = result.apparent_encoding
return result.text
except:
return ""
def parsePage(self):
res = self.getTxt()
newhtml =etree.HTML(res,etree.HTMLParser())
result=newhtml.xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div[3]/ul/li/div[2]/div[1]/a//@href')
return result
class getAvNum():
def __init__(self,url):
self.url = url
def getTxt(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69'
}
try:
result = requests.get(self.url,headers=self.headers,timeout=30)
result.raise_for_status()
result.encoding = result.apparent_encoding
return result.text
except:
return ""
def parsePage(self):
res = self.getTxt()
newhtml =etree.HTML(res,etree.HTMLParser())
rlist=newhtml.xpath('//*[@id="viewbox_report"]/div[1]/span[1]/a[1]//text()')
return rlist
class Bilibili():
def __init__(self,oid):
self.headers={
'Host': 'api.bilibili.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'finger=edc6ecda; LIVE_BUVID=AUTO1415378023816310; stardustvideo=1; CURRENT_FNVAL=8; buvid3=0D8F3D74-987D-442D-99CF-42BC9A967709149017infoc; rpdid=olwimklsiidoskmqwipww; fts=1537803390'
}
self.url='https://api.bilibili.com/x/v1/dm/list.so?oid='+str(oid)
self.barrage_reault=self.get_page()
def get_page(self):
try:
time.sleep(0.5)
response=requests.get(self.url,headers=self.headers)
except Exception as e:
print('获取xml内容失败,%s' % e)
return False
else:
if response.status_code == 200:
with open('bilibili.xml','wb') as f:
f.write(response.content)
return True
else:
return False
def param_page(self):
time.sleep(1)
if self.barrage_reault:
html=etree.parse('bilibili.xml',etree.HTMLParser())
results=html.xpath('//d//text()')
return results
def remove_double_barrage(resultlist):
double_barrage=[]
results=[]
barrage=set()
for result in resultlist:
if result not in results:
results.append(result)
else:
double_barrage.append(result)
barrage.add(result)
return double_barrage,results,barrage
def make_wordCould(resultlist):
double_barrages,results,barrages=remove_double_barrage(resultlist)
with open('barrages.txt','w', -1, 'utf-8', None, None) as f:
for barrage in barrages:
amount=double_barrages.count(barrage)
stt = barrage+':'+str(amount+1)+'\n'
f.write(stt)
stop_words=['【','】',',','.','?','!','。']
words=[]
if results:
for result in results:
for stop in stop_words:
result=''.join(result.split(stop))
words.append(result)
# 列表拼接成字符串
words=''.join(words)
words=jieba.cut(words)
words=''.join(words)
luo=np.array(Image.open('洛天依.jpg'))
w=wc(font_path='C:/Windows/Fonts/SIMYOU.TTF',background_color='white',width=1600,height=1600,max_words=2000,mask=luo)
w.generate(words)
w.to_file('luo.jpg')
def csvdata(data):
with open('top20.csv','w',encoding = 'utf-8',newline='')as csvfile:
fieldnames = ['分类']
writer = csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writeheader()
for i in data:
writer.writerow({'分类':i[0]})
print('ok')
def main():
url="https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3"
urls = getUrl(url)
strUrl = urls.parsePage()
ress = []
for i in strUrl:
AV = getAvNum(i)
oid = AV.parsePage()
ress.append(oid)
csvdata(ress)
if __name__ == '__main__':
main()