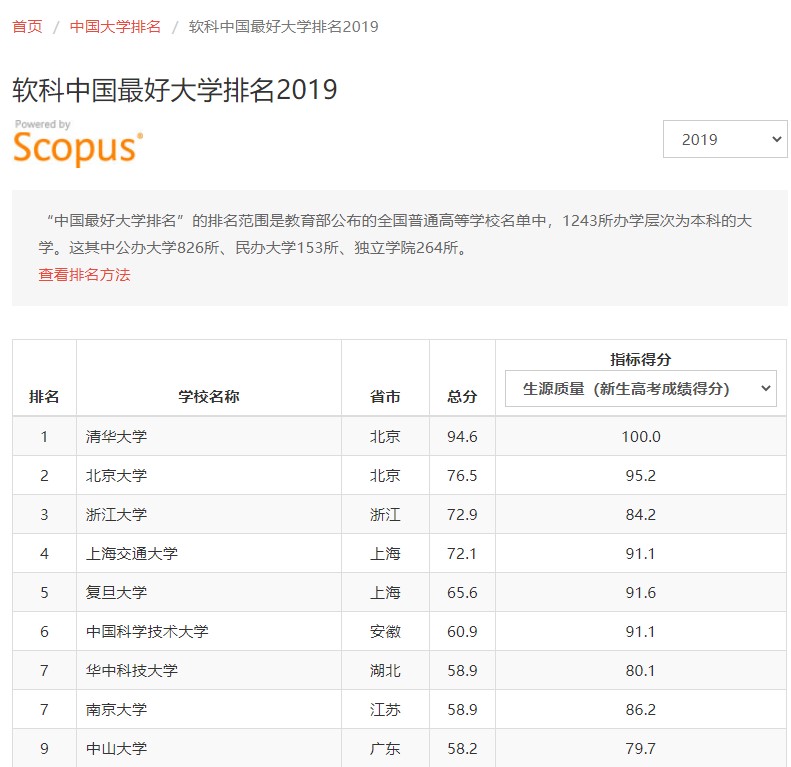
网络爬虫——抓取TIOBE指数前20名排行开发语言
目标网址
TIOBE指数前20名排行开发语言:https://www.tiobe.com/tiobe-index/
说明
TIOBE排行榜是根据互联网上有经验的程序员、课程和第三方厂商的数量,并使用搜索引擎(如Google、Bing、Yahoo!)以及Wikipedia、Amazon、YouTube统计出排名数据,只是反映某个编程语言的热门程度,并不能说明一门编程语言好不好,或者一门语言所编写的代码数量多少。
该指数可以用来检阅开发者的编程技能能否跟上趋势,或是否有必要作出战略改变,以及什么编程语言是应该及时掌握的。观察认为,该指数反应的虽并非当前最流行或应用最广的语言,但对世界范围内开发语言的走势仍具有重要参考意义。

目标数据:(如上表所示)
(1)2020年3月的排名(2)2019年3月排名(3)编程语言(4)评分(5)变化率
明细:
(1)使用urllib或者requests库抓取目标网页中的网页源代码;
(2)使用lxml库中的xpath方法解析源代码,提取上面所示的目标数据,并打印输出;
(3)尝试着使用try..except方法及时捕获异常。
(4)可以尝试将获取的数据保存到文本文件中。
源码
import requests
from requests.exceptions import RequestException
from lxml import etree
def one_to_page(url):
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'
}
try:
response=requests.get(url,headers=headers)
body=response.text
return body
except RequestException as e:
print('request is error!',e)
def parsePage(html):
htmlNew = etree.HTML(html,etree.HTMLParser())
result = htmlNew.xpath('//table[contains(@class,"table-top20")]/tbody/tr//text()')
pos = 0
for i in range(20):
if i == 0:
yield result[i:5]
else:
yield result[pos:pos+5]
pos += 5
def printRank(data):
for i in data:
rank = {
"2020年3月":i[0],
"2019年3月":i[1],
"编程语言":i[2],
"评分":i[3],
"变化率":i[4],
}
print(rank)
def printRankEasy(data):
tplt = "{0:^10}\t{1:^10}\t{2:^20}\t{3:^10}\t{4:^10}"
print(tplt.format("2020年3月","2019年3月","编程语言","评分","变化率",chr(12288)))
for i in data:
print(tplt.format(i[0],i[1],i[2],i[3],i[4],chr(12288)))
def main():
url = 'https://www.tiobe.com/tiobe-index/'
html = one_to_page(url)
data = parsePage(html)
printRankEasy(data)
main()
输出如下