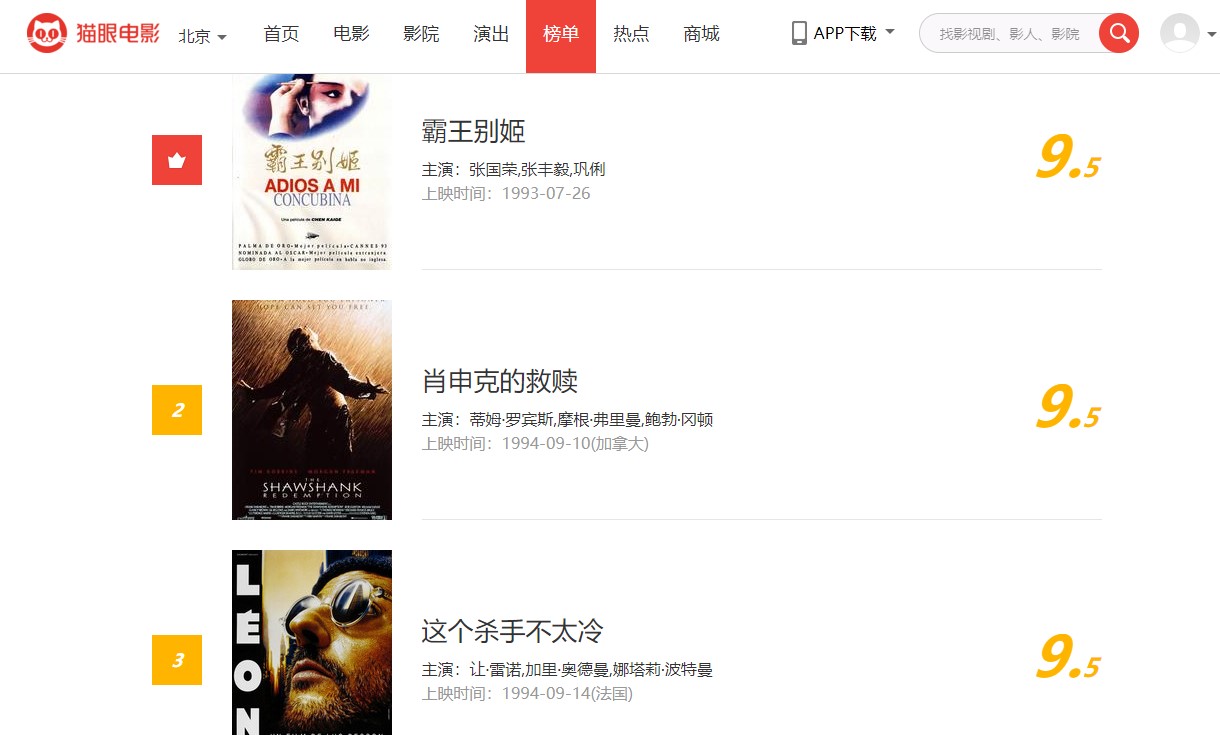
网络爬虫——猫眼电影数据抓取——RE(正则表达式)
猫眼电影榜单网址:https://maoyan.com/board/4
目标数据描述:
(1)排名 (2)电影名称 (3)主演 (4)上映时间 (5)评分
任务要求
(1)使用requests库实现该网站网页源代码的获取;
(2)使用正则表达式对获取的源代码进行解析,并成功找到目标数据所在的特定标签,进行网页结构的解析;
(3)定义函数,将获取的目标数据打印输出,有能力的同学可以试着将结果写入文件中。
(4)使用框架式结构,通过参数传递实现整个特定数据的爬取。
可以使用生成器,将目标数据获取后放到字典中返回,同时,注意观察分页时url的变化,以便获取整个的排行榜数据。建议通过for循环传递变化参数实现。
源码
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
response=requests.get("https://maoyan.com/board/4",headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern= re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?).*?star">(.*?).*?releasetime">(.*?)' + '.*?integer">(.*?).*?fraction">(.*?).*? ',re.S)
items = re.findall(pattern,html)
for item in items:
yield{
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a' , encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'https://maoyan.com/board/4'
html=get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)
输出如下